
AI MBTI判型
"所有模型都是错误的,但其中有些是有用的。" —— 乔治·博克斯
包含大量叠甲请注意!!!
本功能提供两种分类模型(TextCNN、BERT),而非大语言模型。
BERT 的特点,是深度捕捉词语间的上下文关联与逻辑关系,精准理解文本完整语义。它能精准识别文本对观点的态度倾向,清晰区分支持、反对等不同立场,区分局部褒贬词汇影响。
TextCNN 的特点,是捕捉不同分类的用词习惯与词组搭配模式。它的分类逻辑,偏向通过识别标志性关键词、差异化词语权重完成分类,对表层用词敏感度较高,不关注词语的深层语义逻辑。
这种模型决策机制与人类认知存在本质差异。它不遵循符号主义的显性推理路径(如"观察到A现象→依据B规则→推导出C结论"),而是形成一种分布式表征(distributed representation)。当模型输出特定人格类型时,这种判断更接近于经验丰富的MBTI评估师在接触文本样本时产生的直觉反应。
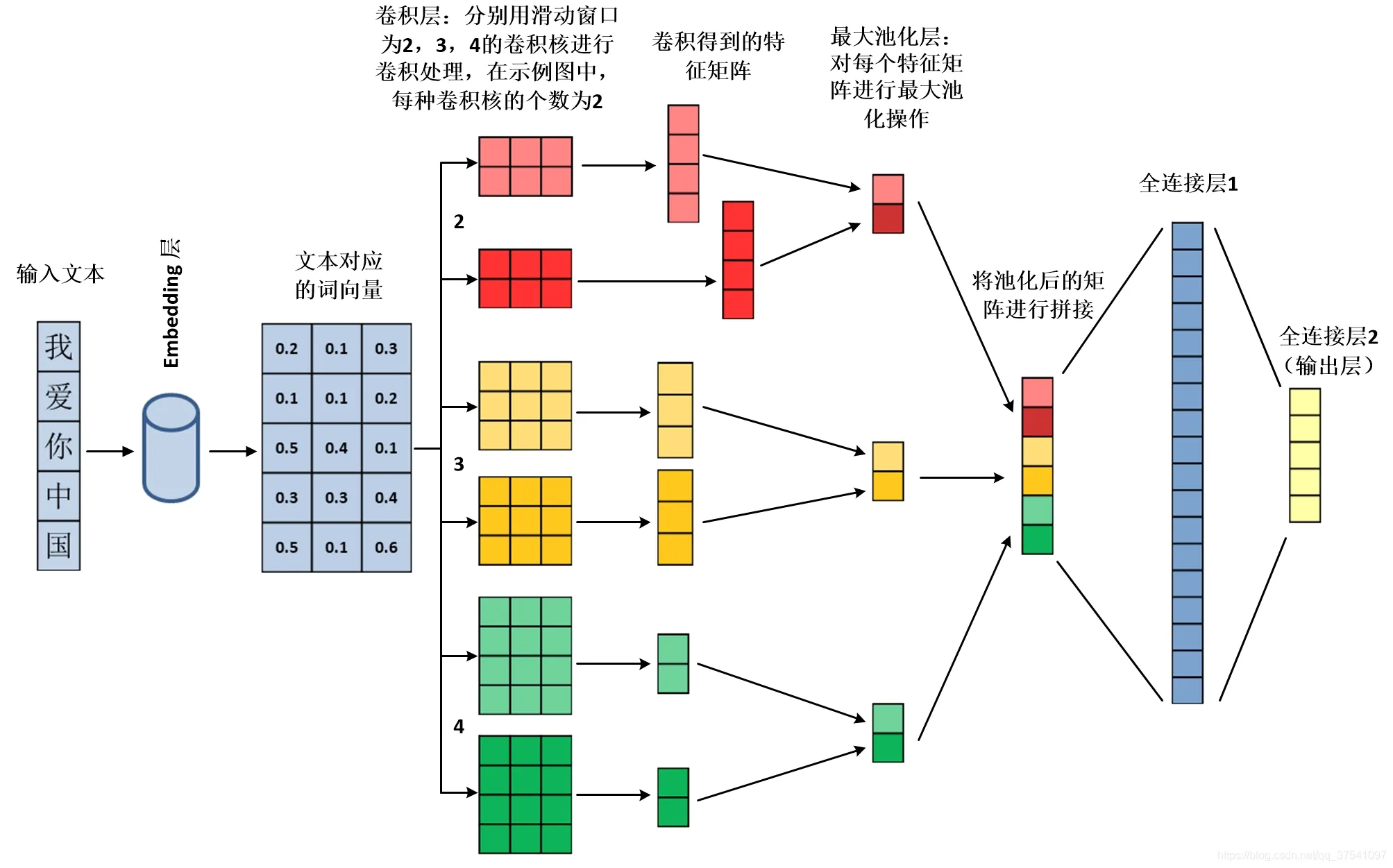 TextCNN原理图
TextCNN原理图模型的训练数据数据来自MBTI互猜活动和本功能反馈数据。训练集的分类依据内容创作者的自判。 如果某类MBTI在创作时频繁出现某一个词(或语义),那么该词可能被模型理解为这个MBTI的特征之一。如果某位创作者多次出现相同冷门词(或语义),那这个词(或语义)可能被理解为对应MBTI的专属词(或语义)。
关于结果:
结果中只包含分类概率,不包含推理逻辑。
如果您需要的是逻辑推理,请使用AI Chat功能。或使用本功能后开启AI Chat,我们会将您在本功能下的最新内容告知大模型。
关于LIME:
我们使用LIME算法通过扰动不同语句,重复测试与原结果进行比对,推断在句子中影响结果的关键句子和其影响度。这仅仅是推导,而非模型的实际逻辑。
在偏向用词的算法(如TextCNN)中,LIME的参考性相对较强。模型可能捕捉到某类人格更频繁使用某类专业词汇,词汇在全文中的位置不影响结果。
在偏向语义的算法(如BERT)中LIME的参考性较弱,因为句子在全文中不同位置上的语义可能截然不同。
关于训练数据:
由于参与互猜的玩家MBTI分布明显不均,某些较少活跃的类型训练数据不足,因此样本分布不均,较少出现的样本容易受到少量参与者个人特点的影响。
本功能偏向娱乐/自判辅助。
训练样本数量如下:
小站正在努力收集样本改进模型,欢迎推荐您身边的现充朋友来使用本功能。我们期待您在结果末尾向我们提交你的自判,让我们共同完善模型。
本功能需扣除金币,详情请点击查看。
巴纳姆效应是心理学家米尔为表对巴纳姆的敬意而命名的一种心理现象。人们会对于他们认为是为自己量身订做的一些人格描述给予高度准确的评价,而这些描述往往十分模糊及普遍,以致能够放诸四海皆准适用于很多人身上。巴纳姆效应能够对不少伪科学如占星学、占卜或心理测验以及抽签掷筊等被普遍接受的现象提供一个十分完全的解释。
但在我看来,这类测验并非毫无用处,就像通过掷硬币做决定的人,意义不在于让硬币替自己作出决定,而在于捕捉自己在抛出硬币的瞬间期待什么。通过测验,你也可以窥见你的潜意识对自己形象的期待。
因此,希望你不要迷信测验的结果,而是对测验的结果和过程加以反思。对于积极的心理暗示,看清楚他是你对自身的期许后付诸行动。对于消极的心理暗示,认清其只是自我暗示,有意的去避免消极暗示的影响。